Some Thoughts on Comparing Classification Models
I end up reviewing a lot of papers on applications of machine learning in drug discovery, and many of these papers are quite similar. The authors will use one or more datasets to compare the performance of a few different predictive models. For instance, a group may compare the performance of some neural network variant with an established method like Random Forest. These comparisons invariably use the same plot that shows a bar chart with the mean value of a metric like the ROC AUC across five or ten cycles of cross-validation. In some, but not all, cases the authors will include a "whisker" showing the standard deviation across the cross-validation cycles. The authors will then point out that their method has the highest mean AUC and declare victory.

One thing I've realized over the last few months is that we don't have many good examples of how to compare classification models. As such, I thought it might be useful to demonstrate a few of the ways that I've been thinking about comparing classifiers. I'm not claiming to have all of the answers. I just want to lay out a few approaches that I've been thinking about. It would be great if we could agree as a community on some best practices.
For this example, I'm going to use a set of hERG data from the ChEMBL database. I assembled this dataset in a manner similar to what is described in my friend Paul Czodrowski's excellent paper, "hERG Me Out." For this particular example, we'll be comparing three popular ensemble learning methods, Extreme Gradient Boosting (XGBoost), Random Forest, and LightGBM. As usual, all of the code and the data used in this post are available on GitHub.
There are several metrics used to evaluate classification models, sensitivity, specificity, accuracy, balanced accuracy, Matthews' Correlation Coefficient, Cohen's Kappa, and more. In this post, we will focus on the Area Under the Receiver Operating Characteristic, also known as ROC AUC or AUC. While it's essential to include multiple metrics showing different aspects of classifier performance, the community seems to have agreed that AUC is the one metric that must be included in any paper.
Confidence Intervals
We'll begin by calculating a confidence interval for the AUC and comparing these confidence intervals. This paper by Anthony Nicholls has an excellent discussion of DeLong's method and how it can be used to define a confidence interval for an AUC. While there is a well-established R package called pROC for calculating confidence intervals and other properties of ROC curves, Python implementations of the method are somewhat scarce. Fortunately, I found this package on GitHub, which provides a Python implementation of DeLong's method. The results are consistent with results obtained with pROC, so it appears to be correct. I copied this code into my Git repo in a file called delong_ci.py and created a function called calc_auc_ci to calculate the AUC with confidence limits.
I haven't seen a standard way of displaying AUCs with confidence intervals in the literature, so I came up with the plot below that shows the AUCs for three methods over 10 cycles of cross-validation. As you can see, the confidence intervals for all three methods overlap in most of the cycles.

Statistical Tests
As Anthony Nicolls points out, the overlap of confidence intervals doesn't necessarily mean that two methods are providing equivalent results. We must perform appropriate statistical tests to invalidate the null hypothesis that results generated by different methods are equivalent.
As I was reading more about the topic, I came across this blog post by Jason Brownlee, which pointed me to a seminal 1998 paper by Thomas Diettrich, one of the pioneers of Machine learning. As Diettrich points out, we can't merely use Student's t-test to compare the AUC distributions across multiple folds of cross-validation. As I pointed out in an earlier post, the t-test relies on three assumptions.
- The data is normally distributed
- The data is drawn from independent distributions
- The variance within the groups is equal within the population
Depending on the dataset, the first and third factors may or may not be true. Since we are using the same training and test sets for all of the methods, the data is definitely not drawn from independent distributions. At this point, we could turn to non-parametric statistics and use the Wilcoxon or related tests, but these tests typically require at least 50 samples. This would require a large dataset and many rounds of cross-validation. Let's see what else we can do.
5x2-fold Cross-Validation
One of the methods suggested by Diettrich is 5 cycles of two-fold cross-validation, where the null hypothesis is tested using a modified version of the t-test. A complete write-up of the modifications to the t-test and the rationale behind the 5x2-fold cross-validation can be found in Diettrich's paper. Fortunately, Sebastian Raschka's mlxtend package has an implementation of 5x2-fold cross-validation, as well as many other useful methods for the application and validation of machine learning models. On a related note, if you're looking for a good, practical introduction to machine learning in Python, I highly recommend Raschka's book. Let's take a look at the p-values we get when we compare results from the three methods listed above.
Method_1 Method_2 p-value XGB RandomForest 0.012 XGB LGBM 0.216 RandomForest LGBM 0.326
If we look at these results, it appears that based on the 5x2-fold cross-validation, we can invalidate the hypothesis that the mean AUC for XGBoost and RandomForest are the same, right? Maybe, there's one more subtle point that we have to consider. Yes, the p-value. 0.012 is less than 0.05, but how many comparisons are we making? Three. Since we're doing multiple testing, we need to adjust our threshold for significance. If we employ something simple like a Bonferroni correction, our threshold becomes 0.05/3 or 0.017. For more information on multiple comparisons, please consult my previous blog post on the topic. Back to our data, it looks like we're ok and we can say that there is a difference between XGBoost and Random Forest.
McNemar's test
Another method that Diettrich suggests for comparing classification models is McNemar's test. One can think of this as a pairwise version of a chi-squared test. In McNemar's test, we begin by creating a contingency table like the one below to compare the performance of model 1 and model 2.

In this table, the regions are:
- a - both models are correct
- b - model 1 is correct, and model 2 is wrong
- c - model 2 is correct, and model 1 is wrong
- d - both models are wrong
We can then compute the chi-square statistic as
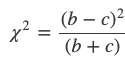
This value can then be transformed into a p-value for people like me who don't typically think in terms of chi-squared values. Luckily for us, McNemar's test is implemented in both the mlxtend and statsmodels Python libraries. As with the confidence intervals above, I couldn't find a definitive way of plotting the data from McNemar's test, so I came up with the visualization below. In the figure, a boxplot is shown for the distribution of p-values from 10 cycles of cross-validation with each of the three pairs of methods. The dashed red line indicates the Bonferroni corrected threshold (0.017) for significance. Based on the plot, we can see that we cannot invalidate the null hypothesis that Random Forest and LGBM are equivalent. If we consider the median AUC, we do see that XGBoost differs from the other two methods.

Please note that this post is called "Some Thoughts on Comparing Classification Models" and not "The Definitive Guide to Comparing Classification Models." I'm still figuring this out and just want to start a dialog. I'm getting tired of reading things like "it is clear that deep learning outperforms more traditional methods" in the introductions to papers. As a field, I think we do a pretty dismal job of evaluating and validating our methods. At this point, I'm not convinced that we've proved anything. It would be great if we could get together as a field and not only agree on standards but also put together code libraries that would enable people to compare methods in a consistent and straightforward fashion. If anyone would be willing to collaborate on something like this, please let me know.



Fantastic post! I agree, not enough people are sampling model performance or comparing the distributions using simple statistical tests. Even choosing model hyperparameters should use a similar procedure, for example: https://xgboosting.com/xgboost-comparing-configurations-with-statistical-significance/
ReplyDelete